使用Heritrix抓取数据

文章目录
Heritrix 是一个由 java 开发的、开源的网络爬虫,用户可以使用它来从网上抓取想要的资源。其最出色之处在于它良好的可扩展性,方便用户实现自己的抓取逻辑。最重要是对于一般的抓取,你是不用碰任何代码的,只要写好配置文件就可以了,简直就是某些人的福音。不过对于一个真正的程序员,代码可是他们的整个生命啊.
原理及特点
深度遍历网站的资源,将这些资源抓取到本地,分析网站每一个有效的URL,并提交Http请求,从而获得相应结果,生成本地文件及相应的日志信息等。
**特点:**Heritrix 是个 “Archival crawler” – 用来获取完整的、精确的、站点内容的深度复制。包括获取图像以及其他非文本内容。抓取并存储相关的内容。对内容来者不拒,不对页面进行内容上的修改(可以通过配置进行过滤)。重新爬行对相同的URL不针对先前的进行替换。爬虫通过Web用户界面启动、监控、调整,允许弹性的定义要获取的URL。
**优点:**Heritrix的爬虫定制参数多
**缺点:**单实例的爬虫,之间不能进行合作。在有限的机器资源的情况下,却要复杂的操作。只有官方支持,仅仅在Linux上进行了测试。每个爬虫是单独进行工作的,没有对更新进行修订。在硬件和系统失败时,恢复能力很差。很少的时间用来优化性能。
安装及使用
下载及文档: https://webarchive.jira.com/wiki/display/Heritrix/
写这篇文章时最新版本为3.2.0,安装方法非常简单,我参考的是官方的文档Heritrix 3.0 and 3.1 User Guide,因为是基于JAVA的,只要有正确的java环境就很容易运行起来。
系统要求:
- **系统:**官方只支持Linux,别的系统理论上也是可以的,我用的是OSX也是OK的;
- **JDK:**官方要求JDK1.6,但我在Linux上用过Openjdk1.7也是OK的,甚至MAC上JDK1.8也没问题,不过推荐还是按照官方要求。怎么安装多个版本的JDK?这不用再说了吧。
- 内存什么的要1G吧,Java Heap默认256M,对于爬虫应该不够,可能会出现out-of-memory异常,可以用JAVA_OPTS来配置jvm的内存。
配置
解压就不用说了,完了之后直接配置使用就行,当然前提JDK环境已经有了。
- 配置环境变量JAVA_HOME,配过的请忽略
|
|
- 配置环境变量HERITRIX_HOME,就是设置Heritrix的主目录
|
|
- 为启动文件设置执行权限
|
|
- 设置JVM的内存占用,这里是1G,也可以更高
|
|
运行
|
|
上面的这条命令就启动了Heritrix,并设置登陆web管理页面的用户名及密码都为admin。当然很有别的参数可以用,查看帮助就好了。
|
|
登陆管理界面:https://localhost:8443
一定注意是https链接,但因为没有证书,所以会出现安全警告,忽略继续访问就可以的。
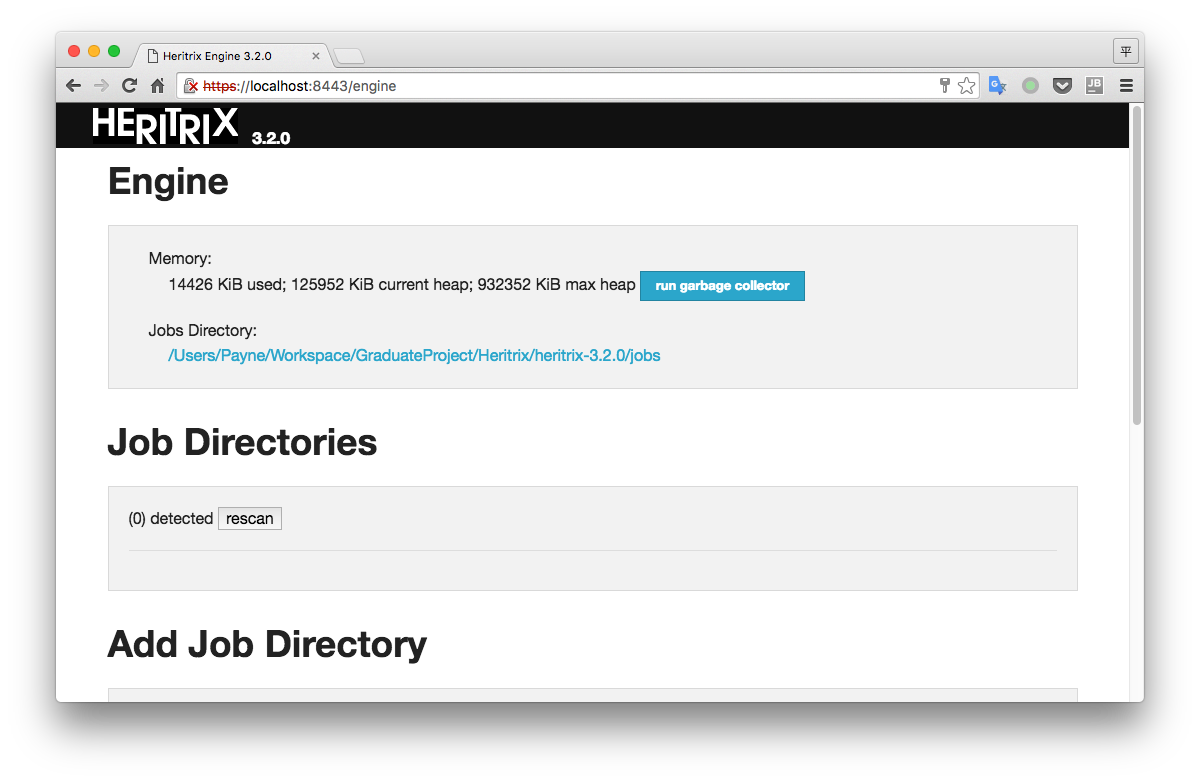
创建抓取任务
在『Add Job Directory』这一项中可以创建新任务或者添加已存在的任务。如下图所示我添加了一个叫做tripsearch的任务。
 点击这个tripsearch就可以进入这个任务的详情页面,如下图所示:
点击这个tripsearch就可以进入这个任务的详情页面,如下图所示:
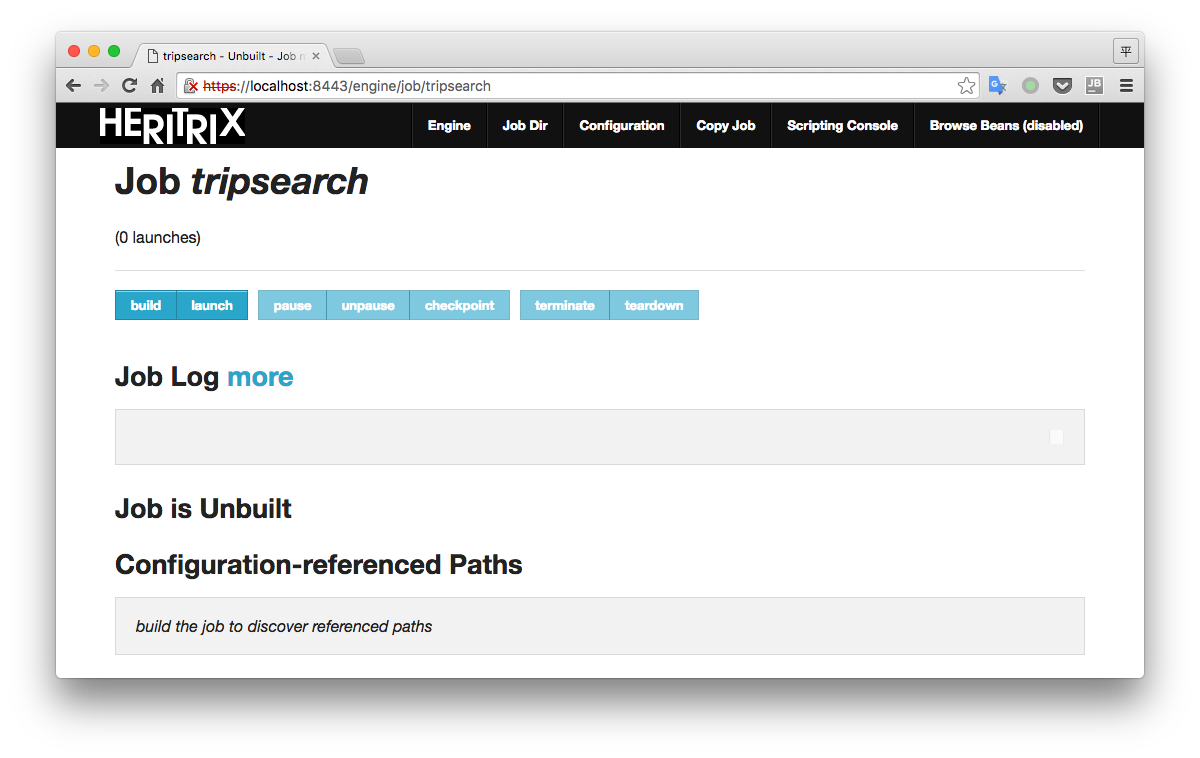 看到上面那些菜单项,最重要的是Configuration,通过一个名为crawler-beans.cxml的配置文件控制整个抓取过程。另外还有些控制按钮,这里也来说下。
看到上面那些菜单项,最重要的是Configuration,通过一个名为crawler-beans.cxml的配置文件控制整个抓取过程。另外还有些控制按钮,这里也来说下。
- build : 构建任务实例
- launch : 启动抓取
- pause : 暂停抓取
- unpause : 从暂停中恢复
- checkpoint : 建立检查点(这个时候会将之前抓到的数据封包备份,如同数据库的checkpoint)
- terminate : 终止抓取任务
- teardown : 删除任务实例
正常的启动流程是:改好配置文件 -> build -> launch。
Heritrix处理流程
Heritrix内部按模块划分成一个个处理器,一个个处理器有序排列,构成处理器链,而处理器链也有序排列。大致可划分为3个处理器链,每个处理器链中又有多个处理器模块。每个URL任务从头走到尾巴,经过各个处理器的处理。
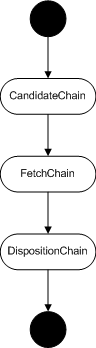
Candidate Chain 主要负责筛选要抓取的URL,然后把它放入抓取队列中。Fetch Chain 主要负责抓取网页内容,提取和解析出内容中的URL。Disposition Chain 主要负责将抓取的内容存储下来,把新的解析出的URL再发送回 Candidate Chain .
参数解释及配置
可以说 crawler-beans.cxml 可以主导整个Heritrix的抓取,采用spring来管理.里面的配置都是一个个bean,通过修改配置文件
crawler-beans.cxml 即可完成几乎所有的需求。
我是要抓取携程各个景点页面,对不多的几个地方进行修改即可实现目标了。
1. 修改任务元数据
|
|
通过文章后面附录中对各个Bean的介绍,simpleOverrides的作用是设置基本的一些任务元数据,我修改的这3个分别是操作人员的联系URL、任务的名字和任务的描述。这些信息在请求页面的时候会带上,告诉对方自己的身份描述信息。身份信息在robots.txt协议中有一定作用,网站可以通过设置该协议来拒绝特定的爬虫。协议具体细节请自行查询。包括是否遵守爬虫的robots.txt协议也可以在metadata里配置。
2. 设置种子站点 种子站点:爬虫从这些页面开始解析出来URL并加入待爬列表中。
|
|
3. 定制爬取范围
Heritrix提供了一种URL匹配的规则模式– SURT。
|
|
通过官方文档中的SURT Rules,+ 表示符合后面表达式的接受,- 表示符合后面表达式的拒绝。表达式http://(com,qq,表示qq.com下的所有子域名都匹配;http://(com,qq,www,)只匹配www.qq.com,不包含子域名;http://(com,ctrip,you,)/sight/表示匹配you.ctrip.com子域名,并且路径为sight下的页面,注意最后的斜杠(slash)不能少。
4. 配置ACCEPT和REJECT规则
每一个规则都由一个Bean来配置。一起组成如下的规则序列。
|
|
一个URL要按顺序由上到下经过各条规则,最终来决定是否接受这个URL,所以规则顺序就非常重要。在经过一条规则的时候,根据规则是拒绝型还是接受型来做不同的处理。如果是拒绝型,则在接受队列中找到符合规则的URL,取出放入拒绝队列中。反之,如果是接受型,则在拒绝队列中找到符合规则的URL,放入接受队列。最终,经过所有规则后,只保留接受队列里的URL。
第一条规则先拒绝所有的URL,然后第二条就是之前配置的SURT规则,接受指定URL路径下的页面。下面的规则就不一一列举了。为了避免已经拒绝了的非所需域名下的链接在之后的接受规则中又被纳入接受队列,注释掉了之后的关于接受的规则。(当然可以把域名过滤的这个规则放在最后一条,最后再过滤掉不符合所需域名的URL)
5. 存储相关
最后是关于写入压缩后的网页内容到硬盘的相关配置。Disposition中的Writer处理器就是处理内容的写入,默认使用的是WarcWriter,warc是Web页面内容的压缩后的格式。Heritrix会把每次请求获得的相关的数据和每次请求的元数据,一条条写入warc文件,并且再用gz做压缩。相关内容的配置如下。
|
|
在上面的Bean可以配置压缩文件的文件名,最大容量,存储路径等等。还有执行的规则,可以拒绝掉不符合规则的内容的存储。warc文件最大容量可以不要设置太大,便于之后我们对数据的处理。一般用默认就行,这里不细说。
附录(各个bean的介绍):
- bean id=simpleOverrides class=org.springframework.beans.factory.config.PropertyOverrideConfigurer 字面上的意思为简单的覆盖,的确这里只是简单的覆盖.设置最基本的信息.如抓取任务名字 (metadata.jobName),操作URL(metadata.operatorContactUrl),描述信息 (metadata.description)
- bean id=metadata class=org.archive.modules.CrawlMetadata 如同simpleOverrides
- bean id=seeds class=org.archive.modules.seeds.TextSeedModule 种子配置,可以从文件中读取种子,也可以直接设置种子
- bean id=scope class=org.archive.modules.deciderules.DecideRuleSequence URL规则控制,可以决定哪些URL要抓取,哪些URL拒绝,URL抓取深度等
- bean id=candidateScoper class=org.archive.crawler.prefetch.CandidateScoper URL范围控制,通过该范围的URL Heritrix方可接受,成为CrawlURI
- bean id=preparer class=org.archive.crawler.prefetch.FrontierPreparer url预处理,如设置URL的抓取深度,队列,成本控制等
- bean id=candidateProcessors class=org.archive.modules.CandidateChain 处理器,引用candidateScoper去控制URL是否可以成为CrawlURI,preparer去设置深度,队列,成本控制等
- bean id=preselector class=org.archive.crawler.prefetch.Preselector 预先选择器,这里会过滤掉一部分URL.如blockByRegex为拒绝正则,allowByRegex为允许正则
- bean id=preconditions class=org.archive.crawler.prefetch.PreconditionEnforcer 先决条件设置,如设置IP有效期,爬虫协议文件robots.txt有效期
- bean id=fetchDns class=org.archive.modules.fetcher.FetchDNS 解析DNS,获得IP
- bean id=fetchHttp class=org.archive.modules.fetcher.FetchHTTP 核心模块,获取URL内容,设置状态
- bean id=extractorHttp class=org.archive.modules.extractor.ExtractorHTTP 核心模块,抽取URL,抽取出新的URL再次运行,如此爬虫才可以一直爬下去
- bean id=extractorHtml class=org.archive.modules.extractor.ExtractorHTML 抽取HTML,包含JSP,ASP等,这里也会抽取JS,CSS等
- bean id=extractorCss class=org.archive.modules.extractor.ExtractorCSS 抽取CSS,无需单独配置,ExtractorHTML会调用
- bean id=extractorJs class=org.archive.modules.extractor.ExtractorJS 抽取JS,无需单独配置,ExtractorHTML会调用