有些小伙伴想在手机上运行大模型,随着手机端芯片性能越来越强,加上蒸馏小模型的表现越来越好,在手机上运行小参数量的小模型也变得有用起来。
芯片的性能
reddit上有人整理了苹果和高通芯片GPU&NPU的算力:NPU information for Apple and Snapdragon
对数值进行了确认和修正
| 处理器型号 | NPU算力 (TOPS, INT8) | GPU算力 (TFLOPS, FP16) | 内存带宽 (GB/s) |
|---|---|---|---|
| A18 Pro | 35 | 4.454 | 60 |
| M2 | 15.8 | 5.68 | 102.4 |
| M2 Ultra | 31.6 | 26.98 | 800 |
| M3 | 19 | 7.1 | 102.4 |
| M4 | 38 | 9.2 | 120 |
| M3 Max | 35 | 32.8 | 300 |
| M4 Max | 38 | 34.08 | 546 |
| 骁龙8 GEN2 | 26 | 4.178 | 67.0 |
| 骁龙8 GEN3 | 34 | 5.548 | 76.6 |
| 骁龙X Elite | 45 | 9.2 | 133.9 |
| 骁龙8 Elite | 75 | 6.758 | 76.6 |
可以看到最新的骁龙8 Elite的NPU性能已经超过了M4 Max,GPU性能接近M3,内存带宽跟桌面级M系列比相对弱鸡,但超过了iPhone的A18 Pro,整体上看确实比较能打,如果能够使用NPU来做大模型推理,那速度肯定是飞起,就算是用上GPU,速度也能提升不少。
手机运行大模型总览
手机平台的方式
由于手机平台没桌面平台方便,使用起来稍微麻烦些,不过也有命令行和GUI两种方式。
| 应用/项目名 | 适用平台 | 使用资源 | 交互方式 | 简介 |
|---|---|---|---|---|
| Termux+Ollama | Android | NPU+CPU | 命令行 | 安卓的终端模拟器,通过proot-distro可以模拟各种Linux发行版。Ollama是最常用的大模型运行工具之一,能够通过Termux安装,并利用Ollama CLI来执行大模型任务。 |
| ChatterUI | Android | CPU | GUI | 基于llama.cpp和llama.nr开发,以在相同模型下提供最快的响应速度而著称。 |
| PocketPal | Android, iOS | CPU | GUI | 同样基于llama.cpp和llama.nr,注重用户体验设计,但在性能上略逊于ChatterUI。 |
| mlc-chat | Android, iOS | GPU | GUI | 基于mlc-llm框架构建的图形界面应用程序,支持GPU加速功能,但当前版本仅为演示性质,实际使用体验不佳。 |
| mllm | 高通Android平台 | NPU+CPU | GUI | 利用高通QNN框架优化了大型语言模型在移动设备上的运行效率,特别适用于搭载骁龙8Elite处理器的手机,在特定条件下(如1.5B参数规模时)可实现高达1000 tokens每秒的速度。 |
顺便也列一下桌面平台的
桌面平台比较成熟,MacOS和NVIDIA GPU平台都是一键运行。
常见方式及开源项目如下:
- llama.cpp ggerganov/llama.cpp
- Ollama ollama/ollama
- LMStudio lmstudio.ai
- gpt4all nomic-ai/gpt4all
- transformers huggingface/transformers
- LocalAI go-skynet/LocalAI
各个工具的特点:
- 追求性能/无GPU:选
llama.cpp或mlc-llm。 - 开发者友好:选
Ollama或Transformers。 - 图形界面需求:选
GPT4All或Text Generation WebUI。 - 兼容OpenAI生态:选
LocalAI。
手机纯CPU推理
Termux+Ollama (CPU)
对于熟悉命令行的朋友来说,这种方式非常方便,可玩性比较强,但只能用CPU推理
安装Termux
注意:不要用Play Store安装,这个版本有一些限制
准备环境
- 安装ssh server,方便在电脑上操作, 官方教程
手机操作:
|
|
电脑操作:
|
|
- 准备Linux的模拟环境
|
|
proot-distro的安装是从github下载的,如果速度很慢可以通过其他方式,例如Github Proxy服务手动下载,然后把文件放到$PREFIX/var/lib/proot-distro/dlcache,如果路径不存在要新建mkdir -p $PREFIX/var/lib/proot-distro/dlcache。参考
使用Ollama运行大模型
|
|
如果直接安装Ollama网速比较慢,那就手动去下载,选包含arm的那个包。同样也可以用Github Proxy让下载加速。
Ollama模型的存储位置是:~/.ollama/models/, 采用的是类似docker的分层镜像模式, 元信息manifests在 ~/.ollama/models/manifests/registry.ollama.ai/library/deepseek-r1,真实文件在.ollama/models/blobs, 不过文件名都是hash字符串,可以通过文件大小判断是哪个模型,或者查看manifests的json文件,"mediaType": "application/vnd.ollama.image.model"的那项就可以看到模型文件的hash。
如果我想在别的软件用这个模型,这样就不用重复下载,该怎么做呢?
- 退出Ubuntu模拟器,回到Termux环境,执行
exit - 申请手机的存储权限,执行
termux-setup-storage,然后手机会弹窗确认,允许即可 - 找到Ubuntu的存储位置,
cd $PREFIX/var/lib/proot-distro/installed-rootfs/ubuntu/root/,这就是ubuntu环境的root目录,然后再执行cd .ollama/models/blobs找到模型文件可以将模型复制到APP可公共访问的位置~/storage/
安装pocketpal运行(CPU)
安装方式:
- Apple AppStore或者Google Play Store安装
- Github下载
下载模型:
- 直接下载:Models页面,如果没有想要的模型,右下角加号,可以直接从HuggingFace下载
- 加载本地模型:Models页面,右下角加号,选择本地模型,选择模型文件
注:这个应用的性能有点问题,同样的模型,ChatterUI能做到10token/s, 它只能到5token/s,都是用的 llama.cpp和llama.nr
安装ChatterUI运行(CPU)
安装方式:
加载模型:
- 加载本地模型:左侧菜单Models,添加模型,选择用外部的模型即可
手机GPU推理(MLC-LLM)
MLC-LLM简介
MLC-LLM(Machine Learning Compilation for Large Language Models):是一个机器学习编译器和高性能部署引擎,用于为大语言模型开发、优化和部署AI模型。本项目的任务是使每个人都能够使用机器学习编译器和高性能部署引擎,并使用机器学习编译器和高性能部署引擎开发、优化和部署AI模型。旨在通过编译优化 和硬件适配 ,将大模型(如 GPT、LLaMA 等)高效运行在多种设备上(包括手机、边缘设备、浏览器等)
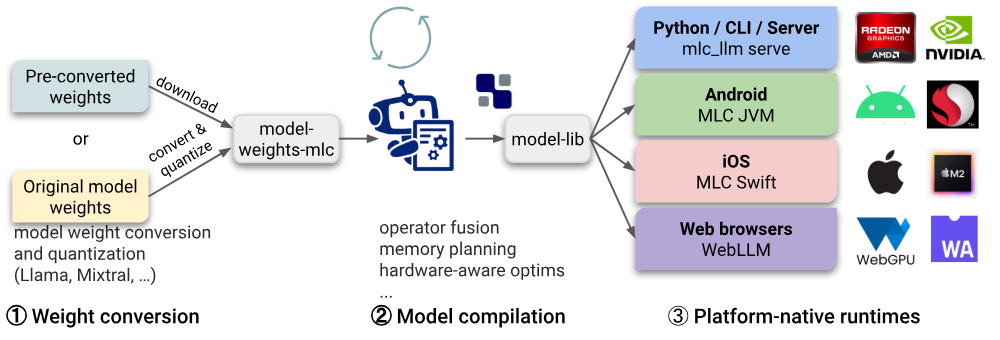
- 跨平台编译优化
- 通过机器学习编译(MLC)技术,将大模型的计算图优化为适应不同硬件(CPU/GPU/移动端等)的高效代码。
- 支持模型量化(如 4-bit 量化)、算子融合等技术,显著降低模型推理时的内存占用和计算成本。
- 无需依赖特定框架
- 与 PyTorch 或 TensorFlow 等框架解耦,直接编译为原生二进制文件,提升部署灵活性。
- 本地化与隐私保护
- 支持在本地设备(如手机、树莓派)运行大模型,避免依赖云端服务,适合对隐私敏感的场景。
- 开源生态支持
- 基于 Apache TVM 社区,提供开放的工具链(如
mlc-llm项目),支持多种模型架构(LLaMA、Vicuna 等)。
- 基于 Apache TVM 社区,提供开放的工具链(如
Apache TVM简介
Apache TVM(Tensor Virtual Machine):是一个开源的深度学习编译器,用于编译和部署深度学习模型。它提供了一种灵活的方式来优化和部署深度学习模型,支持多种后端(如 CPU、GPU、NPU 等),并支持多种编程语言(如 Python、C++ 等)。
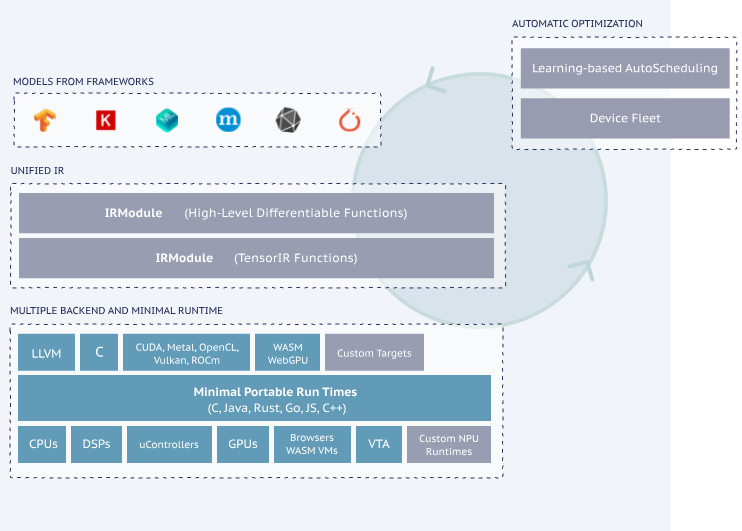
这里的知识比较深,我还有没深入去了解,如果有编译原理的知识应该会更容易理解

大概的流程就是先读取模型的计算图,然后转换为中间表达(IR),然后经过一系列优化,例如Schedule 优化、AutoTVM自动调优,最后使用LLVM框架生成面向各端的优化代码。
LLVM框架在各个语言的编译器实现中比较常见,新的编程语言基本都用的这个作为编译器的后端,例如Golang和Rust。
上面图中显示的步骤比较详细,我们逐个来简单介绍下,详细介绍请看官方文档
- 各种模型格式的导入
- 转换为Relay语言,Relay 是神经网络的功能语言和中间表示(IR)。
- 降级为张量表达式(TE)表示,张量表达式(TE)是一种用于描述张量计算的领域特定语言。
- 使用auto-tuning模块AutoTVM或AutoScheduler对TE进行优化
- 为模型编译选择最佳配置
- 降级为张量中间表示(TIR,TVM 的底层中间表示)。根据最佳配置将 TE 子图降级为 TIR 并进行底层优化
- 编译成机器码。根据不同平台的工具链,将模型编译为可链接对象模块,然后轻量级 TVM runtime 可以用 C 语言的 API 来动态加载模型
使用MLC-LLM编译模型
官方的Demo应用 预置了几个模型,但下载下来运行会崩溃

可以看到就是GPU可用内存超了,GPU可用内存6422.678MB,而模型权重是953.503MB,临时缓冲区是11099.183MB,所以可用内存不足,需要减小模型权重或者临时缓冲区的大小。在后续的编译过程中调小 --prefill-chunk-size 和 --context-window-size 可以解决这个问题。
- 准备环境
过程比较麻烦,这里就不再重复,直接看官方文档即可,主要的内容有:
- 安装Rust
- 安装Android Studio,配置SDk和NDK
- 安装LLVM
- 安装TVM Unity runtime
- 配置各种环境变量
|
|
- 模型转换
将官方发布的模型转换为MLC格式
|
|
- 生成模型配置
生成MLC模型的配置文件
|
|
- 编译并构建
|
|
- apk构建
上机运行
想上手试试的可以从夸克网盘下载, 打包了deepseek-r1-1.5b-q4的模型,安装即可对话,无需下载模型文件 链接:https://pan.quark.cn/s/a25c8dfbfa13 提取码:Dyw6
这个应用只是一个Demo,后续我会适配一下pocketpal或者ChatterUI
手机NPU+CPU推理(mllm)
支持的加速方式: ARM NEON, x86 AVX2, Qualcomm NPU (QNN)
支持使用 Qualcomm QNN 运行 Qwen-1.5-1.8B-Chat,以在搭载 Snapdragon 8 Gen3 的设备上获得 Hexagon NPU 加速。QNN 环境设置和设计的详细信息可以参考 这里。
预填充阶段由 QNN 和 CPU 共同完成,而推理阶段则由 CPU 完成。
这块我还没有试验过,本身来说高通的QNN还不太稳定,后续有空可以试下。
小结
如果能用上 骁龙8 Elite 75 TOPS的算力来跑大模型那确实很值得期待,不过比较大的限制是内存大小和带宽,手机的内存通常是12G或者16G,系统通常也会限制GPU和NPU能使用的内存大小, 加上内存带宽比较小,能跑的最大模型估计还是INT4量化的7B模型,智能程度有点低。
当然动态量化的方案,让小尺寸的模型也有比较的性能,这是比较期待的