在本项目中,为了更好的模拟真实的生产环境,对于SolrCloud技术不采用伪集群方式,而是真正实现一个搜索集群,当然由于笔者只是学生,没有资金租用多台服务器来搭建集群,因此借助于Docker的容器技术在一台服务器上虚拟出逻辑上的六台主机。
在阅读本节之前,需要对Docker技术和SolrCloud的基础知识有一定的了解,可以参考一下链接。
java环境镜像制作
本项目中的java环境基于ubuntu镜像,除了jdk还安装了必要的工具,例如vim,ifconfig,ssh等。
已经做好的镜像可以从docker hub或者上拉取
1
| docker pull xuping/ubuntu_java
|
运行镜像
1. 在运行镜像之前,要先建立容器要挂载的目录。在本项目中,我在系统根目录新建data目录,并在该目录包含如下目录,其中solr*为三个solr实例的程序执行目录,其中zookeeper*为三个zookeeper实例的执行目录。
1
2
3
4
5
6
7
8
9
10
11
12
| root@iZ2880wp05zZ:/data# tree -L 1
.
|-- conf
|-- data
|-- exe
|-- jetty
|-- solr1
|-- solr2
|-- solr3
|-- zookeeper1
|-- zookeeper2
`-- zookeeper3
|
solr*目录中放置Solr的可运行程序,其实就是solr安装目录,需要做的修改是将solr安装目录下bin/solr.in.sh,将ZK_HOSTS的值改为zookeeper的地址,在本项目中就是ZK_HOSTS=”zoo1:2181,zoo2:2181,zoo3:2181”,去掉注释使之生效。
zookeeper*目录中放置Zookeeper的可运行程序,这里需要修改的是zookeeper安装目录下conf/zoo.cfg(新建),以及在data目录下新建myid文件,并写入当前服务的id,例如server.1就在myid中写入1。
1
2
3
4
5
6
7
8
9
| tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/data
clientPort=2181
server.1=zoo1:2888:3888
server.2=zoo2:2888:3888
server.3=zoo3:2888:3888
|
2. 运行镜像,启动zookeeper实例:
1
2
3
4
5
6
| docker run -d --name zoo1 -h zoo1 -v /data/zookeeper1:/data -v /data/exe:/exe xuping/ubuntu_java /bin/bash /exe/zooRun.sh
docker run -d --name zoo2 -h zoo2 -v /data/zookeeper2:/data -v /data/exe:/exe xuping/ubuntu_java /bin/bash /exe/zooRun.sh
docker run -d --name zoo3 -h zoo3 -v /data/zookeeper3:/data -v /data/exe:/exe xuping/ubuntu_java /bin/bash /exe/zooRun.sh
|
解释:
- run 运行镜像
- -d 保持后台运行
- –name zoo2 -h zoo2 镜像的运行实例,即container的名字和主机名都为zoo2
- -v /data/zookeeper2:/data 挂载宿主机的/data/zookeeper2文件夹到container中的/data
- xuping/ubuntu_java 要运行的镜像
- /bin/bash /exe/zooRun.sh 在镜像启动时,要运行的命令。
3. 运行镜像,启动Solr实例:
1
2
3
4
5
| docker run -d --name solr1 -h solr1 -v /data/solr1:/data -v /data/exe:/exe xuping/ubuntu_java /bin/bash /exe/solrRun.sh
docker run -d --name solr2 -h solr2 -v /data/solr2:/data -v /data/exe:/exe xuping/ubuntu_java /bin/bash /exe/solrRun.sh
docker run -d --name solr3 -h solr3 -v /data/solr3:/data -v /data/exe:/exe xuping/ubuntu_java /bin/bash /exe/solrRun.sh
|
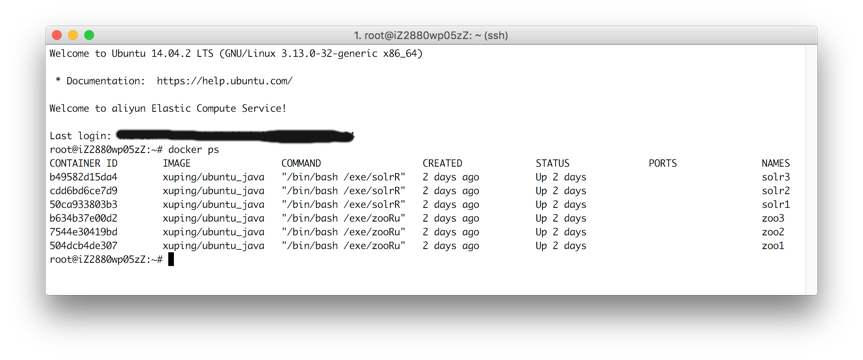
4. 通过docker ps查看运行的容器,如果运行成功即会看到本文开始的那张图片。
5. 由于我们没有定制docker容器的网络,虽然同一台机器上的容器默认在同一网络中,但其网络是自动分配,需要将各自的ip进行同步。利用docker的挂载功能,将同一目录挂载到所有容器,这样即可用脚本来同步所有容器的网络信息,其脚本如下所示,作用不仅是同步网络,另外也是保持容器后台持续运行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| service ssh start #启动ssh服务
/data/bin/zkServer.sh start #启动zookeeper服务
local_ip=`/sbin/ifconfig -a|grep inet|grep -v 127.0.0.1|grep -v inet6|awk '{print $2}'|tr -d 'addr:'`
host_item=$local_ip' '`hostname`
echo $host_item >> /exe/hosts
input="/exe/hosts"
while true;
do echo update hosts;
echo '' > /etc/hosts
while IFS= read -r var
do
echo "$var" >> /etc/hosts
done < "$input"
sleep 10;
done
|
同样的,在Solr实例中也有类似的脚本。
创建collection
通过ssh连接上任意一个solr实例,转到solr安装目录。
1. 上传配置文件到Zookeeper中
1
| server/scripts/cloud-scripts/zkcli.sh -zkhost zoo1:2181,zoo2:2181,zoo3:2181 -cmd upconfig -confname trip -confdir ./conf
|
解释:
- -cmd upconfig 表示操作是上传配置
- -confname 表示在Zookeeper中的配置文件所放的路径
- -confdir 表示本地要上传的配置文件的路径
2. 通过Url API来创建collection
1
| wget http://solr1:8983/solr/admin/collections?action=CREATE&name=trip&numShards=3&replicationFactor=3&maxShardsPerNode=5&collection.configName=trip
|
解释:
- action=CREATE 动作为创建collections
- name=trip collection的名字为trip
- numShards=3 分片数量为3
- replicationFactor=3 复件个数为3
- maxShardsPerNode=5 每节点最大分片个数为5
- collection.configName=trip 要创建的collection在zookeeper中的配置文件的路径
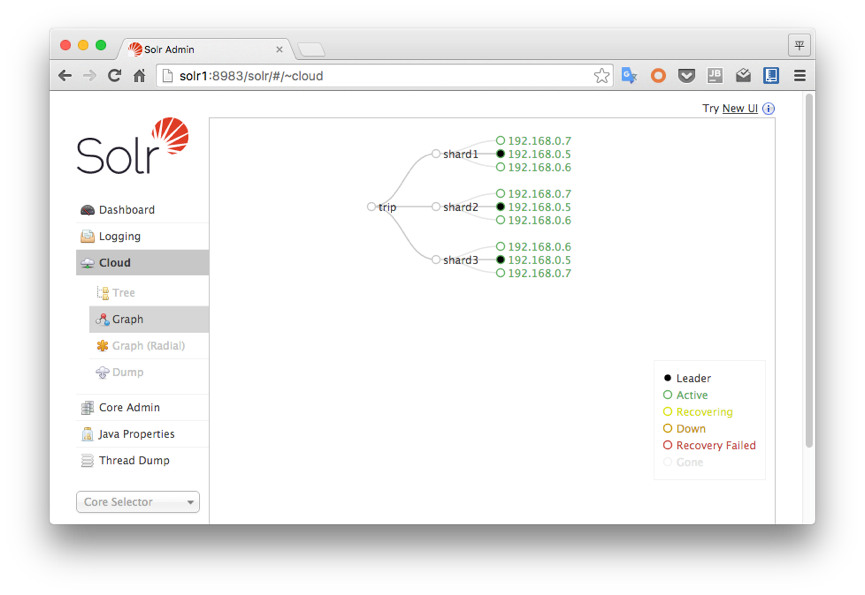
成功之后,访问任一solr节点的管理界面,会看到如下所示的样子。(当然前提是你的浏览器要和这些节点在同一网络内,无论是代理,还是VPN都能实现)
建立索引
还是选择从mysql中导入数据,和单机情况下的导入一样,配置文件不需要改变,直接像单机情况下使用即可。
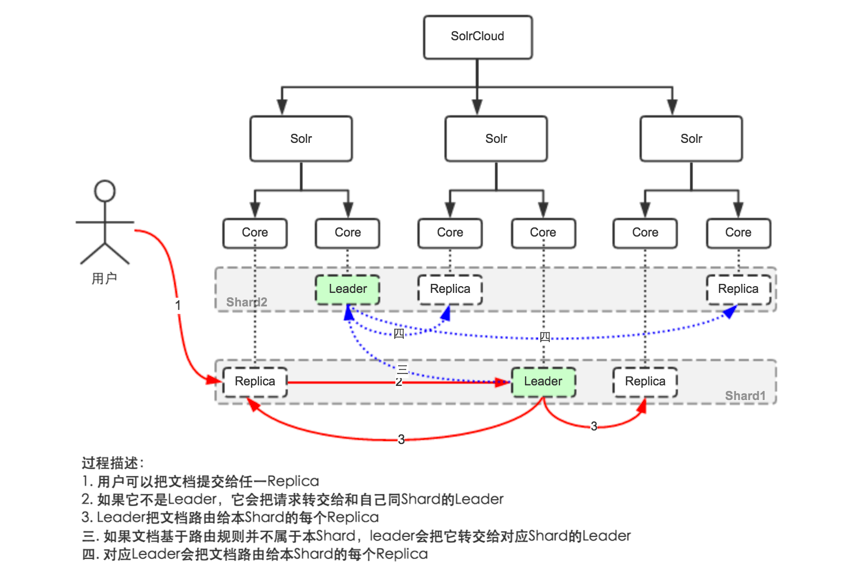
当然后台的一些情况还是不同于单机版的,其实流程也比较清晰,我们暂时不用管怎么实现这些的,只管了解即可。
查询
只用修改连接的实例即可,其它部分和单机情况下一样。
1
2
| String urlString = "zoo1:2181,zoo2:2181,zoo3:2181";
SolrClient solrClient = new CloudSolrClient(urlString);
|
